What Is a Large Language Model?

Large Language Models (LLMs) now underpin most of the AI tools people use daily, from chatbots to coding assistants. This guide explains what an LLM actually is, how it works, which problems it solves, and where techniques like vector search and RAG fit into the wider architecture. As someone who has spent more than a decade working with data engineering and model-serving pipelines, I’ll walk you through the core components, common pitfalls, and the real-world infrastructure patterns teams use to deploy these systems at scale.
We’ll explore how LLMs are trained, how tokens work, why embeddings matter, inference optimisation, hallucination risks, and how retrieval-augmented generation plugs into WordPress and enterprise content workflows. If you want the deeper architectural view, see our AI infrastructure blueprint, which outlines full model hosting patterns.
This article covers: model architecture, transformer attention, pre-training, fine-tuning, inference pipelines, evaluation, limitations, and how vector stores support RAG for WordPress. These topics match the expectations of modern AI literacy and follow the same structure used by engineering teams building production AI systems.
What Problem Do Large Language Models Solve?
Before transformers arrived, language AI relied on systems that struggled with long-range context and domain-specific nuance. RNNs and LSTMs could only look a few steps back. Bag-of-words models didn’t understand meaning. Rule-based systems required constant human input.
Large Language Models solve three critical problems:
- Understanding natural language without manual rules.
- Generating coherent output across long sequences.
- Transfer learning from general knowledge to specific tasks.
Because they’re trained on vast text corpora, LLMs learn statistical patterns of grammar, reasoning, relationships, and world knowledge. This allows them to perform tasks they weren’t explicitly programmed for: summarisation, analysis, translation, classification, coding, content generation, and more.

In short: LLMs provide a universal, flexible interface over textual knowledge and reasoning, dramatically reducing the cost of building “intelligent” software.
How Large Language Models Work: The Simplest Explanation
An LLM is essentially a gigantic probability machine. Given a sequence of words (or tokens), it predicts the next most likely token. Everything else – creativity, reasoning, structured outputs, coding – emerges from this single predictive mechanism.
The modern LLM architecture is based on the transformer, introduced by Google in 2017. The transformer changed AI because it replaced sequential processing with parallel attention, allowing models to scale to trillions of parameters.
Transformers at a Glance
Transformers use three key concepts: embeddings, attention, and feedforward networks.
Embeddings
Words are converted into dense numerical vectors. These vectors capture semantic meaning – “king” and “queen” are more similar than “king” and “car”. If you want a deeper breakdown, our vector databases explained guide covers how embeddings power retrieval and search.
Self-Attention
Self-attention lets each token “look” at every other token in the sequence and determine which pieces matter most. Rather than reading text left-to-right like older models, the transformer understands relationships globally.
This solves the long-context problem that crippled RNNs. A transformer can understand how the start of a sentence relates to the end, or how a financial statement connects its footnotes.
Feedforward Layers
After attention mixes information, feedforward layers refine, compress, and combine the signals through many stacked blocks. Each block adds more capacity to learn deeper relationships.
Stack enough of these layers, give them enormous training data, and you end up with an LLM capable of surprising behaviours.
What Are Tokens
LLMs don’t work with words directly. Instead, text is broken into small units called tokens. These can be whole words, sub-words, or even characters depending on the tokenizer.
Why this matters:
- A model with a 32k token context window can only “see” that many tokens at once.
- Longer inputs mean higher compute costs.
- Tokenisation affects model accuracy and coherence.
When people talk about “prompt engineering”, they often mean structuring tokens in a way that activates the model’s desired behaviour.
How Large Language Models Are Trained
Training an LLM involves three main phases: pre-training, fine-tuning, and RLHF.
Pre-Training: Learning General Knowledge
Pre-training is where the model consumes petabytes of text and learns to predict the next token. No task labels. Just predictions. This gives the model broad world knowledge, grammar, facts, and styles.
Fine-Tuning: Becoming Specialised
Fine-tuning teaches the model to perform specific tasks such as:
- medical reasoning
- coder assistance
- legal analysis
- financial modelling
This can use supervised examples or distilled knowledge from larger models.
RLHF: Aligning Output With Human Preferences
Reinforcement Learning from Human Feedback adds an alignment layer: the model learns which answers humans prefer. This reduces harmful or low-quality behaviour.

Inference: How LLMs Generate Text in Real Time
Inference is the process of generating tokens one by one. At scale, inference is far more complex than training. Production teams must optimise:
- batching
- caching
- quantisation
- speculative decoding
- GPU vs CPU hosting
For a full walk-through of how inference clusters are built, see our engineering-focused AI infrastructure blueprint.
Why LLMs Sometimes Hallucinate
Hallucination means producing plausible but incorrect output. It happens because:
- The model predicts text, not truth.
- Its training data may contain errors.
- Its internal world model is incomplete.
- It may confidently fill gaps when unsure.
Hallucination cannot be eliminated entirely, but it can be reduced using grounding techniques like RAG and evaluation frameworks.
Where Vector Databases Fit Into the LLM Stack
LLMs are powerful but limited by their training cutoff and context window. Vector databases solve both problems by storing embeddings from your documents, enabling semantic search and retrieval.
A vector store:
- indexes your content as embeddings
- supports similarity search
- feeds relevant context into an LLM
- keeps responses accurate and up to date
If you’re building applications on WordPress or headless CMS stacks, our RAG for WordPress guide covers implementation patterns using Pinecone, SQLite, FAISS, and more.
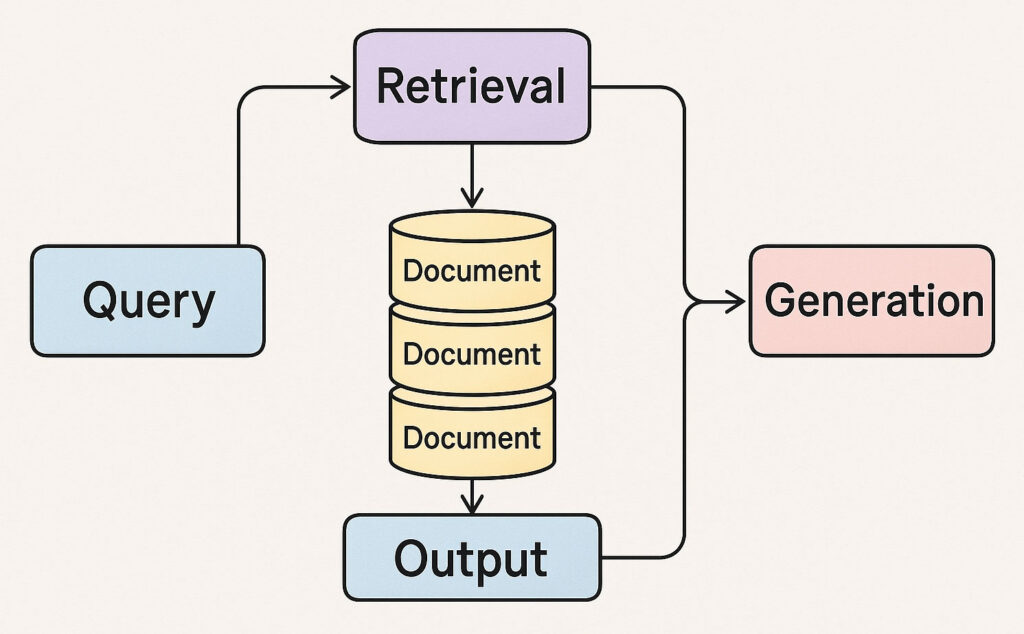
What Is RAG (Retrieval-Augmented Generation)?
RAG is a method that retrieves external content during the generation process. Rather than relying solely on the model’s memory, it pulls in your documents, databases, or knowledge base.
This dramatically reduces hallucination and lets teams deploy smaller, cheaper models without sacrificing accuracy.
The RAG pipeline looks like:
- User query → embed
- Vector search retrieves relevant documents
- LLM receives prompt + retrieved context
- Model generates grounded, validated output
Key Limitations of Large Language Models
Despite enormous capability, LLMs come with constraints:
- Context limits — models can only “see” a fixed number of tokens.
- Lack of real-time data — without RAG or API tools, responses may be outdated.
- Hallucination — predictions, not facts.
- Compute cost — inference becomes expensive as scale grows.
- Opacity — internal representations are difficult to interpret.
Common Misconfigurations and Pitfalls
Across production deployments, I repeatedly see the same issues:
1. Over-sized Models
Teams choose a huge model without evaluating whether a 7B or 13B parameter model could achieve similar accuracy with RAG support. This leads to inefficiency and inflated hosting bills.
2. Poor Prompt Hygiene
Long, unstructured prompts waste compute and reduce accuracy. Prompting should be treated like API design: consistent, modular, and predictable.
3. No Vector Index Maintenance
RAG systems degrade when embeddings aren’t refreshed after content updates. Periodic re-embedding is essential.
4. Missing Observability
Without logs, scoring, or tracing, you cannot diagnose failures or hallucinations. Production LLMs require monitoring as much as any microservice.
5. Storing Wrong-Sized Embeddings
Using large embedding dimensions in small semantic tasks wastes memory and slows queries. Align embedding size with retrieval complexity.
6. Ignoring Token-Level Costs
Chat UIs hide the true cost of long prompts. In production dashboards, token budgeting is a non-negotiable skill.
Checklist for Teams Deploying LLMs
Here is a concise, practical checklist based on real deployments:
- Choose the smallest viable model for your task.
- Implement retrieval early (RAG) to reduce hallucinations.
- Use a vector database optimised for your workload.
- Quantise weights to reduce compute cost.
- Monitor token usage aggressively.
- Set up logging, evaluation, and output scoring.
- Re-embed and re-index content regularly.
- Cache all repeated inference paths.
- Run load tests before public release.
- Use guardrails for safety-critical outputs.
Real-World Applications of LLMs
- Customer support automation
- Content generation and summarisation
- Code generation and review
- Data extraction from documents
- Chatbots and assistants
- Search enhancement using semantic understanding
- Knowledge base consolidation
- Personalised recommendations
Most modern applications combine LLMs with vector search, making technologies like vector databases explained an essential part of the AI stack.
The Future of Large Language Models
Three trends define the evolution of LLMs in 2025 and beyond:
1. Smaller, Smarter Models
Fine-tuned and distilled models increasingly outperform massive general models at domain-specific tasks.
2. Long-Context Models
Models capable of handling millions of tokens are emerging, reducing the need for chunking and external retrieval in some use cases.
3. Multi-Modal Intelligence
LLMs now integrate text, images, audio, and video understanding into a single reasoning system.
What Is a Large Language Model FAQs
They don’t “understand” in a human sense, but their statistical modelling of patterns often produces meaning-aligned behaviour.
No. They complement them. Search retrieves facts; LLMs transform and interpret them.
Transformers rely heavily on matrix multiplication, which GPUs accelerate dramatically.
For accuracy on proprietary or up-to-date data: yes, almost always.
Yes. Many teams integrate them using plugins, API calls, and structured RAG workflows. Our RAG for WordPress guide covers this.
Final Thoughts
Large Language Models represent a breakthrough in how we interact with information. From transformers and attention to embeddings and retrieval, understanding the moving parts helps you build more reliable and cost-effective AI systems. Whether you’re creating a WordPress knowledge assistant, an enterprise chatbot, or an AI-powered search feature, the foundation remains the same: high-quality embeddings, optimised inference workflows, careful prompt engineering, and robust observability.
If you found this content helpful,please consider sharing!:
More in AI
